 Update: Watch out for public servers not announcing the leap second! In the last few minutes we have been observing a number of public servers (even stratum 1) that don’t announce the leap second. If the majority of your upstream doesn’t announce the leap second, your clients won’t trigger it. If that’s your case, you can use ntpd’s leapfile directive and a leap second file to provide your own servers with the correct information. Check the ntpd documentation for more information.
Update: Watch out for public servers not announcing the leap second! In the last few minutes we have been observing a number of public servers (even stratum 1) that don’t announce the leap second. If the majority of your upstream doesn’t announce the leap second, your clients won’t trigger it. If that’s your case, you can use ntpd’s leapfile directive and a leap second file to provide your own servers with the correct information. Check the ntpd documentation for more information.
Update: Miroslav Lichvar has counted the public servers that are announcing the leap second on a per-country basis. You can find his stats on pastebin.
I have been running simulations for the upcoming leap second for a few weeks now. While some mysteries haven’t been solved yet, I was finally able to put together a configuration for our servers and clients that satisfies to the following requirements (where do these requirements come from? That is explained further down in the article):
- it works on Debian Linux Squeeze, Wheezy and Jessie
- it keeps the Linux kernel out of the game, in order to avoid triggering unknown kernel bugs
- it avoids backward steps of the clock
- the clock converges to the right time in an acceptable amount of hours
- it doesn’t hog public services
What this solution doesn’t provide: this is neither Google’s leap smear nor Amazon’s: you use standard ntpd code with no changes; this is not a fast clock slew as chrony’s either. Servers/clients have evolved predictably during most of the simulations and shouldn’t diverge too much from each other, but there are conditions where you may observe offsets between them in the order of magnitude of 0.1s. That should still be bearable though and will still save you from the headache of kernel bugs or jumps back in time. In order to work properly, this solution must make a few assumptions:
- you have at least four internal NTP servers, synchronized with at least four public servers and/or internal specialized time sources
- your clients use at least four of your own internal NTP servers and no external NTP server
- you use unicast NTP packets (broadcast and multicast will probably work as well or even better, but they haven’t been tested in my simulations)
- you are using ntpd (the reference implementation) version 4.2.8p3 (earlier versions have a bug that will make our countermeasures against clock stepping ineffective)
Let’s look at the implementation on both server and client side, which is pretty similar but with a few important differences.
Server configuration
As summarised above, it’s extremely important that you have at least four sources, as this will ensure that you have a fairly good convergence speed without hogging public services by increasing the number of requests you make. Those who provide public NTP sources do it for free, please respect them and anyone else that’s using the same sources. Once you install ntpd 4.2.8p3 you’ll need to add these directives to your servers’ configurations:
disable kernelto keep the kernel out of the waytinker step 0to avoid steppingrlimit memlock 0to work around the fact that ntpd and Linux are not best friends sometimes…
You should deploy this configuration earlier than June 30th (UTC). Keep a copy of your old configuration to roll back these changes after the leap second has been handled, but notice that if you’ll keep 4.2.8p3 you should also retain the rlimit directive.
Client configuration
As summarised above, it is extremely important that you use at least four sources that you control and no other. This for two reasons: one is convergence speed (just like the case for the servers), the other is that public services or services out of your control will likely step while yours won’t and the resulting behaviour of your clients will be unpredictable. That said, once you install ntpd 4.2.8p3 you’ll need to add these directives to your clients’ configurations:
disable kernelto keep the kernel out of the waytinker step 0to avoid steppingrlimit memlock 0to work around the fact that ntpd and Linux are not best friends sometimes…- besides, at the end of each server or peer directive you will add a
maxpoll 8directive to increase the frequency of the requests that your clients will perform against your servers. Please don’t do that with any public NTP source, ever! Depending on how many clients and servers you have in your own premises, you may even usemaxpoll 7or 6 but beware that the number is an exponent:maxpoll 8means that the larger interval between two polls to a time source will be 2^8 = 256 seconds;maxpoll 7means 128 seconds at max,maxpoll 6means 64 seconds: put in a value that is too small and you will hog your NTP servers, storm your network with NTP packets and degrade the service for all your clients — not really a good idea.
You should deploy this configuration earlier than June 30th (UTC). Keep a copy of your old configuration to roll back these changes after the leap second has been handled, but notice that if you’ll keep 4.2.8p3 you should also retain the rlimit directive.

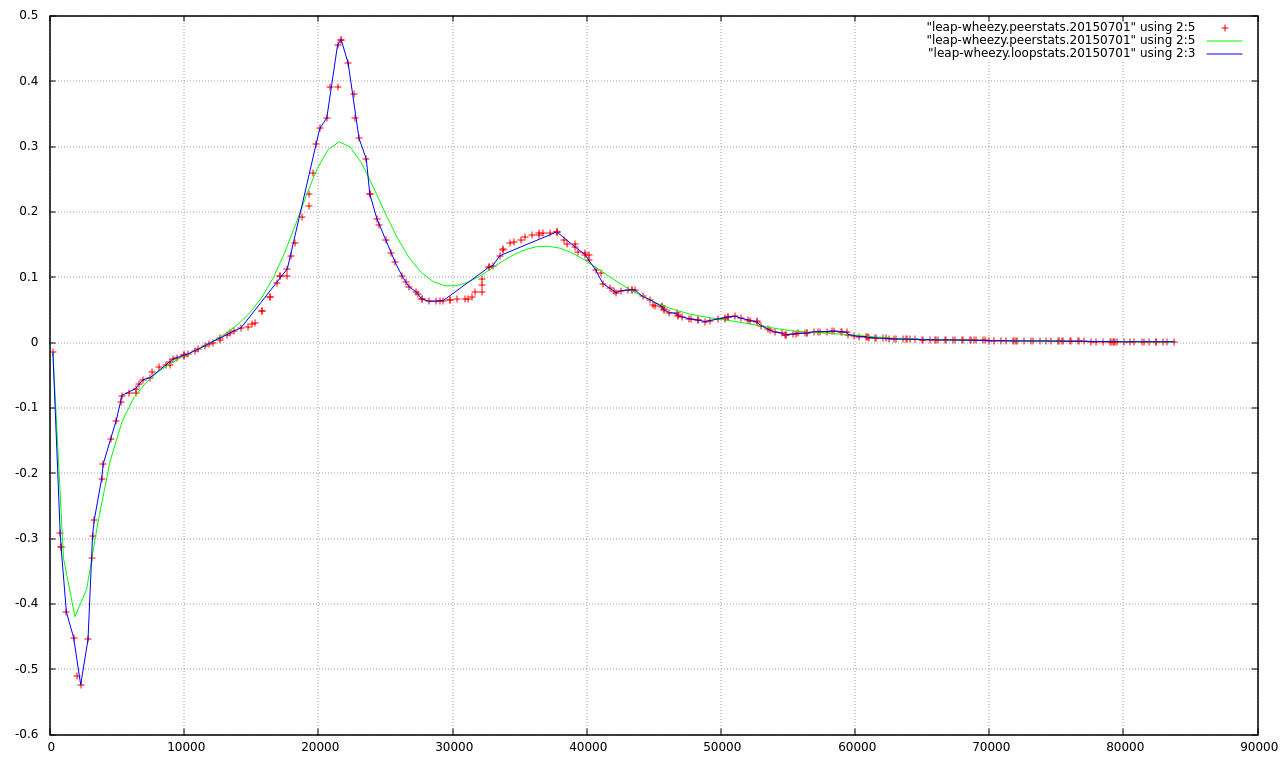
The graph shows how an NTP server has converged during a 24h experiment: the red crosses are polls of this server against its references, the green line is a Bezier curve that approximates the polls, the blue line comes from ntpd’s loopstats and indicates the evolution of the offset for the server
How the leap second will be handled
At this point I will assume that you have deployed your new configuration in good time. Let’s look at the timeline of the events that you can likely expect (timestamps in UTC, ISO8601 format): 2015-06-29T01:00:00Z: the public NTP sources will start propagating a leap warning to their clients: briefly after this time your servers will receive the warning every time they poll their sources and will propagate the same information to your clients; if you have applied the disable kernel directive the Linux kernel won’t be requested to arm the leap second; 2015-06-30T23:59:60Z (circa): the leap second is inserted; at the first poll against the public sources, your servers will find themselves one second ahead and will start to slow down the clock soon after; your clients will notice what will appear an instability of your servers to them and they will also start slowing down;
The graph shows how an NTP client (of an internal server) has converged during a 24h experiment: the red crosses are polls of this client against a test server, the green line is a Bezier curve that approximates the polls, the blue line comes from ntpd’s loopstats and indicates the evolution of the offset for the client. Notice how the waves are higher (bigger offsets) and larger than the correspondent graph for the server.
2015-06-30T23:59:60Z+20000/30000 seconds: by this moment, your servers should have crossed the offset 0 from your sources, went up to ~0.4s behind their references and started to converge towards offset 0 again; the offset will still make “waves” but they will be smaller and smaller so don’t get desperate if you observe that, after a while, the offset appears to grow again. The behaviour of the clients will be similar, but with higher and longer waves for the offset than the servers; for clients, 30000 seconds may not be enough to show a good convergence, but they’re getting there. Some time between 2015-07-01T17:00:00Z and 2015-07-03T00:00:00: in this interval, both your servers and your clients should have an offset of 0.01s or smaller (unless their clock is very unstable, for some reason), which makes it safe to restore the original configuration and restart ntpd. Congratulations: you’ve handled the leap second with no backward steps in time.
Why these requirements
We have stated our requirements at the beginning of this article. Our solution is designed so that:
- it works on Debian Linux Squeeze, Wheezy and Jessie
- it keeps the Linux kernel out of the game
- it avoids backward steps of the clock
- the clock converges to the right time in an acceptable amount of hours
- it doesn’t hog public services
And here is why.
it works on Debian Linux Squeeze, Wheezy and Jessie
It’s the biggest part of our installations, simple as that.
it keeps the Linux kernel out of the game
In 2012, a certain part of the headaches for the leap second came from a kernel bug that was triggered by the leap second announcements on heavily loaded systems. That bug has been fixed but we can’t exclude there are others today. To play it safe we don’t tell the kernel about the leap second and let ntpd handle it separately
it avoids backward steps of the clock
Many applications, programs, even programming languages work on two assumptions:
- time is monotonic (there are no steps back in time)
- a minute always lasts for 60 seconds
Assumption 1 is false on Linux because the Linux kernel handles the leap second insertion by stepping the clock one second back when it’s approaching 23:59:60. Assumption 2 is false in general — it is no less false than the statement “a year is 365 days” or “February is 28 days”: true most of the times but not always. Any program that relies on any of these assumptions is likely to “get confused” when the leap second will be inserted. By avoiding a step back of the clock we make the time appear to be monotonic and the minute when the leap second is inserted appear to last 60 seconds.
the clock converges to the right time in an acceptable amount of hours
The first edition of Google’s leap smear took 24 hours to smear the leap second, this year’s edition takes 20. Considering how “homemade” our solution is, anything that converges in a comparable time is good enough. In most of our experiments we had a good convergence (offset below 0.01s) in some 17 hours. Even a time interval double than that (34 hours or even more) is also acceptable, because the service is still functional and the system clock is managed.
it doesn’t hog public services
This should be rather obvious, but if it isn’t: you don’t abuse someone that is providing a service for free. No, not even for a short time. Never. There is no good reason, there is no good excuse. Never.

The leap-lab at Opera (2015)
Our test environment and simulations
The leap lab at Opera is built on the following hardware:
- seven old Dell PCs (Optiplex 745 or 755)
- a small Cisco switch
- a USB keyboard
- a Dell screen as old as the PCs
The only thing that is new in this lab is the keyboard. OK, some of the network cables are new, too 😉 Two PCs were installed with Debian Squeeze, three with Wheezy and two with Jessie. They are all in the same LAN and connected to the same switch (the one under the long green cable in the picture). Depending on what I wanted to test, some PCs would simulate upstream servers, some internal servers and some clients. In the latest experiment I am running while writing this post it’s three upstreams, three internal servers and one client but I have experimented with several different combinations. The baseline configuration for the machines has been applied with CFEngine, with some part disabled so that we won’t mess up with production systems (e.g.: you don’t want to send the central rsyslog server messages with timestamps in the future, not that it would break but… why do that?). That was particularly easy thanks to the hENC, the external node classification system we have developed and we use with CFEngine. One of the PCs in the lab has also the role of CFEngine policy hub. CFEngine is very lightweight so that doesn’t have a big impact on the experiment. The configuration of ntpd itself is managed via CFEngine and hENC. This has allowed us to set up test scenarios very quickly: every time I wanted to set different roles for the machines or change certain parameters for the experiment I did that in hENC, deployed the files on the policy hub and CFEngine delivered the right configuration to each machine. CFEngine also installed the prerequisite software packages (e.g.: ntp, ntpdate, make…), programs (e.g. adjtimex) and scripts needed to run the experiments. To run the simulations in sync, I used clusterssh to connected and send commands to all machines simultaneously. The sequence of actions to be performed (e.g.: clean up files from previous experiments, set the clock to June 30th, 23:30, apply the new configuration…) were described in a Makefile, so that when I wanted to, say, start an experiment it was enough to get into the machines and just run make test on all of them. ntpd was configured to log statistics, which I grabbed from all machines with rsync and graphed using gnuplot. The graphs you see in this article and that I’ve also tweeted from time to time are produced from standard loopstats and peerstats files using gnuplot.
Instrumentation for the simulations
Besides CFEngine, hENC and make I’ve also used scripts I developed myself. They are now on github for your convenience. In the repository on github you’ll also find binaries for adjtimex. adjtimex is distributed together with Debian so the presence of those binaries deserves an explanation. When you install adjtimex from the deb package, an installation script is also run to calibrate the clock. It would be a really nice idea, if it wasn’t that the calibration should be done only on a machine with no load at all. Most of the time, the calibration will mess up with the system clock speed in a way that even ntpd may have trouble in fixing. Since adjtimex is an invaluable tool for leap second simulations but I don’t want to incur in the calibration mess, I distributed the adjtimex binary “on the side”, using CFEngine to deploy it in /usr/local/sbin. You can either use the copy that I put on github for your convenience, or extract it yourself by using apt-get install --download-only adjtimex to download the package, and dpkg -x to extract the contents without installing the package.

Pingback: An humble attempt to work around the leap second | A sysadmin's logbook
Hi bronto, thanks for your interesting article, tests and observations. I do not know much about ntp and always try to keep things as simple as possible. Up to now I assumed that ntpd as a client with ‘-x’ option would do the job.
I didn’t test the “leap second case” yet, but when running the ntpd from the default debian package (4.2.6) with ‘-x’ in /etc/default/ntp on squeeze and wheezy client hosts, a test offset of one second (date -s ‘now + 1 second’) showed the time divergence from your server graph above and should disable “kernel time discipline” like setting leap second indicator flags (as long as you believe in man pages 😉 ).
Without ‘-x’, ntpd stepped the second back at once because the offset is larger than 128ms.
Hi Piet, thanks for your comment
According to documentation, -x and tinker step 0 do exactly the same thing. However, versions prior to 4.2.8p3 would step anyway for a leap second and -x/tinker step 0. That seemed to be a known bug that has been fixed in that version. You should try and simulate with a leap second properly (e.g. with a leapfile) with your version and see what happens.
Besides, if you find out that -x and tinker step 0 aren’t doing the same thing you should also report that. I chose to go for a configuration change because I had to change it anyway, so it was better to change just one file (ntp.conf) than two (both ntp.conf and /etc/default/ntp). That’s the only reason why I’m not using -x.
Ciao!
— bronto
Hi bronto
Tests done. You are right. -x and tinker are doing the same thing and stepping the leap second in version 4.2.6.p2 resp. 4.2.6.p5. Thanks for the hint.
Piet
You’re welcome! And good luck!
Hello,
thank you so much for sharing this awesome information.
I would just like to comment that starting ntpd with the option “-x” is almost the same than using the “disable kernel” and “tinker step 0” ntpd.conf options 🙂
Regards,
Pablo
Hi Pablo
That is correct: -x and tinker step 0 do the same thing, and that also disables the kernel discipline. I thought I wrote that I add “disable kernel” to make it explicit but I see it was not in this post so it’s probably in the company’s wiki.
Good luck for tomorrow 😉
Ciao
— bronto