
Note: this article is now obsolete, please have a look at A humble attempt to work around the leap second, 2015 edition. Thanks.
Some background
Back in March, I talked about the experiments I was conducting to manage the leap second coming at the end of June 30th, 2012. Despite the fact that the leap second was first introduced in the early 70s, and that we never had a negative leap second up to date, a number of applications and systems still rely on some wrong assumptions, namely:
- every minute always lasts 60 seconds
- time read from the system clock is monotonic
- two consecutive reads of a UNIX timestamp, happening at least one second after the other, will result in the second timestamp being bigger than the first one (rephrase of the previous point in the UNIX/POSIX world)
So bad that, after exactly fourty years from the first leap second, systems and applications still rely on these assumptions and can crash badly when, during a leap second insertion, they find themselves in a situation they didn’t expect.
David Mills, the inventor of NTP, in his document “The NTP Timescale and Leap Seconds” suggests how it should implemented on all systems that always assume 60-second minutes. If that was correctly implemented in, e.g., the Linux kernel, we’d have no need to work around any issue, as time would still be monotonic during the leap second transition. Unfortunately, that is not the case, and Linux will suddenly step back one second when the clock reaches July 1st, 2012, 00:00:00.
The procedure described below will help you to avoid the step, and to recover for the excess second the clock will find itself to have compared to its time sources. However, this procedure is far from ideal in a number of situations, and if you decide to apply it on your systems you do it at your own risk. My advice is: go for this procedure only where the risk of having a system crash due to a leap second is higher than the risk of a misbehavior due to two systems having an offset of some tenths of a second; and do that only after some testing. …
Description of the preliminary tests
Purpose of preliminary tests was to find a way to disarm the leap second in the kernel.
When ntpd detects that a leap second should be inserted at the end of the day, it arms it in the kernel, and sets a flag so that clients can get this information and do the same. Once the leap second is armed in the kernel, it will survive to ntpd, meaning that you can’t avoid the clock step back one second by simply killing ntpd: you need to disarm the leap second in the kernel.
After some research and tests, I discovered that:
- adjtimex is one tool you can use in Linux to arm/disarm the leap second in the kernel
- the change may not happen instantly, so you better do it in good time.
The relevant section of the man page are the following:
-p, --print
Print the current values of the kernel time variables.
. . .
For Linux kernels 2.0 through 2.6, the value is a sum of
these:
1 PLL updates enabled
2 PPS freq discipline enabled
4 PPS time discipline enabled
8 frequency-lock mode enabled
16 inserting leap second
32 deleting leap second
64 clock unsynchronized
128 holding frequency
256 PPS signal present
512 PPS signal jitter exceeded
1024 PPS signal wander exceeded
2048 PPS signal calibration error
4096 clock hardware fault
. . .
-S status, --status status
Set kernel system clock status register to value status.
Look here above at the --print switch section for the
meaning of status, depending on your kernel.
As you can see, the status reported by adjtimex is a “bit string”, and the relevant bits for our case are the fifth (16) and the sixth (32)… well, actually just the fifth in our case, but we’ll consider the sixth also, for completeness.
If we wanted to reset the leap second we’d need to:
- get the status using –print
- check if one of the leap second bits is set
- calculate a new value by resetting those bits to zero
- use –status to set the new value
This simple Perl script does exactly that:
#!/usr/bin/perl
use strict ;
use warnings ;
use constant DEBUG => 0 ;
my $adjtimex = q{/sbin/adjtimex} ;
open my $cmdpipe, "$adjtimex --print |" ;
if (not defined $cmdpipe) {
die "Hell, cannot read from $adjtimex pipe" ;
}
my $status ;
while (my $line = <$cmdpipe>) {
my ($keyword,$value) = ($line =~ m/^s*(.+): (.+)$/) ;
next unless $keyword eq q{status} ;
$status = $value ;
last ;
}
if (not defined $status) {
die "Cannot read status from $adjtimex" ;
}
# We try to detect if a leap second is inserted (16) or deleted (32)
# We AND the status string with 48 (32+16) and we expect $leap to be
# either 0 (those bits are down), or 16 (leap second inserted), or
# 32 (leap second removed). Theoretically, we could also get 48, but
# that would mean that we are both inserting and removing a leap second
# at the same time, which is illogical.
my $leap = $status & 48 ;
if ($leap == 0) {
# No leap set, we "fail" out
exit 1 ;
}
if ($leap == 16 or $leap == 32) {
# Leap second inserted (16) or deleted (32): we must reset that bit
$status -= $leap ;
system($adjtimex,'--status',$status) ;
exit 0 ;
}
die "Leap bits are set to $leap, which is illogical" ;
It is simple enough, commented, and doesn’t use anything external (libraries, commands) but adjtimex. It could be made better, especially for the system() call: feel free to improve it.
A few more experiments showed that five minutes are enough for the status change to settle.
At this point I had a way to avoid the step change at midnight. It was time to turn to ntpd. I would stop it before resetting the leap second bit, and restart it after midnight with a slightly different configuration: in order to avoid ntpd making a step adjustment, you either have to change the configuration file to add a tinker step directive, or (easier) run ntpd with an additional -x option.
Description of the procedure
Equipped with these results, I set up a test environment with:
- a server with a leap seconds file configured
- a client
- scripts like the one above
- configuration files for different purposes
- a crontab file
- a makefile to glue everything together
A test cycle would comprise the following steps:
On the server:
- stop ntpd
- set the server clock to June 30th, 2012, 23:45:00
- copy the appropriate configuration file in place
- start ntpd
On the client: first install all the needed stuff (perl script, crontab file in /etc/cron.d, ntp keys for multicast, ancillary software…), and we are ready to roll:
- stop ntpd
- copy the appropriate configuration files in place
- sync the client with the server in a step change
- start ntpd
And what about the contents of the crontab file? Well, that’s where the real procedure is actually implemented. Here we go:
# m h dom mon dow user command 54 23 30 06 * root /etc/init.d/ntp stop 55 23 30 06 * root /usr/local/sbin/leap-adjust.pl 01 00 01 07 * root /usr/sbin/ntpd -p /var/run/ntpd.pid -g -u ntp:ntp -x 01 00 02 07 * root /etc/init.d/ntp restart
It should be now clear what’s going to happen around midnight, so I’ll skip it, and concentrate on statistics instead.
Yes, statistics: we needed to know how the clock would recover once it found itself one second ahead: how fast? in which way? how predictably? can we improve on that by changing the configuration?
There is a very simple way to get statistics from ntpd: just activate them in the configuration, and you get them for free. That is as simple as including these few lines in the configuration file:
statsdir /var/log/ntpstats/ statistics loopstats filegen loopstats file loopstats type day enable
To visualise how things were going, I used gnuplot to plot columns 2 and 3 of the loopstats file.
With all this in place, it was time to test the procedure and see what happens.
Procedure test and results
I did the first two tests using an unicast configuration, over IPv6 (for reasons I won’t discuss here), and actually inserting a leap second, see above.
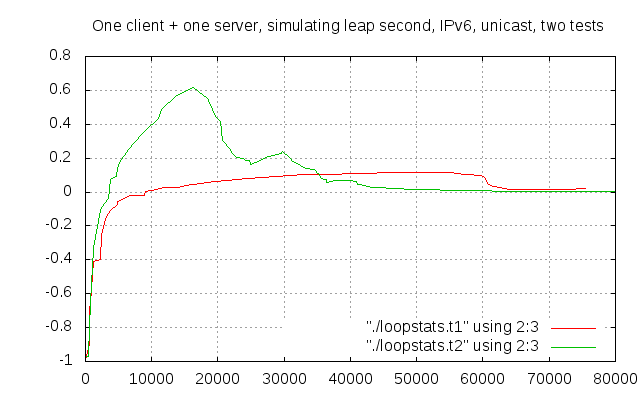
The first test was nice and good: the client took some time to recover, but after crossing the x axis it stayed well under 0.2 seconds offset.
Unfortunately, that was not the case of the second test in the same configuration: the clock ran to zero too quickly, and it started converging only after it reached more than 0.6 seconds offset. Good news was that it crossed the other test’s line quite early (around 35000 seconds into the test, less than 10 hours) and stayed well below that line for the rest of the time. So we could say that in this second test convergence was quicker, but at the price of an higher offset.
It was time to repeat the test again, but this time over IPv4. I repeated the test three times, and that didn’t change things much:
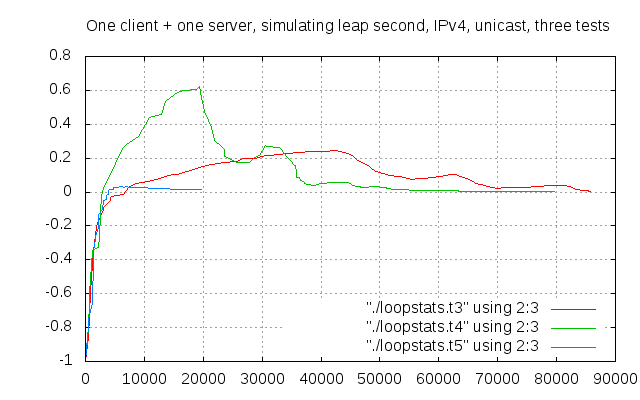
The first two tests in this configuration went more or less the same way as the first two with IPv6. The third was so good that I could stop it after less than 20000 seconds (about 5 and a half hours).
What could we deduce from these first 5 runs? Basically, two things:
- IPv6 doesn’t affect the results, which are in all similar to those you get on IPv4
- convergence speed is not related to the maximum offset (tests t2, t4, and t5 show quick convergence, but t5 is markedly different from t2 and t4);
- worst scenario would be having different patterns across clients, so that they may be offset by about half a second between each other
Now I wanted to test this procedure on my standard setting, that is: multicast NTP over IPv4, with four servers in my LAN. Unfortunately I didn’t have four test servers, so I faked the leap second on my workstation by using the standard date command and kicking the clock forward by one second. I did it three times, and the results were nice enough:

Very nice indeed: the three lines overlap so much that you can barely tell the green line from the other two. Why was that? It was because of multicast? Or because I had four servers instead of just one? Or, again, because my workstation has been sync’d for a long time (while the test machines were not), and ntpd had a reliable frequency rate saved in ntp.drift?
It was time to discover it, so I changed the game again: I converted the test server into a client, and I used the kick-the-clock trick so that I could run two unicast tests simultaneously against our four servers. And here we go:
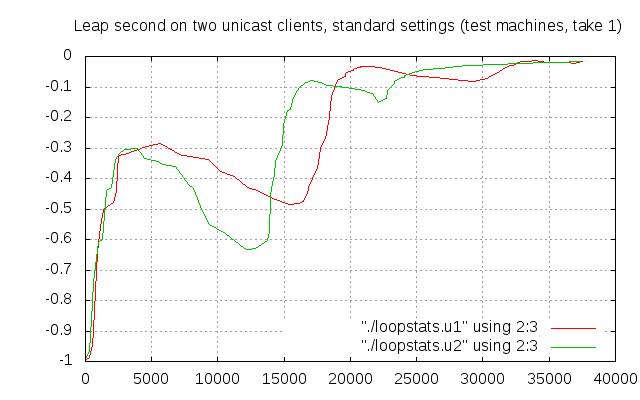
Quite strange pattern, isn’t it? And with the two clients reaching an offset of about 0.5 seconds between each other.
Was it because they’ve been jumping back and forth in time because of the leap second simulations? Let’s try once again:
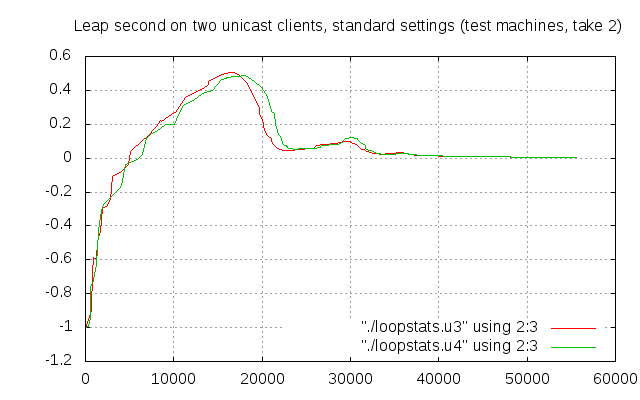
Much better. We know this pattern from before, and the time the clients converge for good is again close to 35000 seconds. But that 0.5 offset from UTC is so bad…
Now, let’s see how they perform when used as multicast clients. Same trick again: multicast configuration, and a kick to the clock.
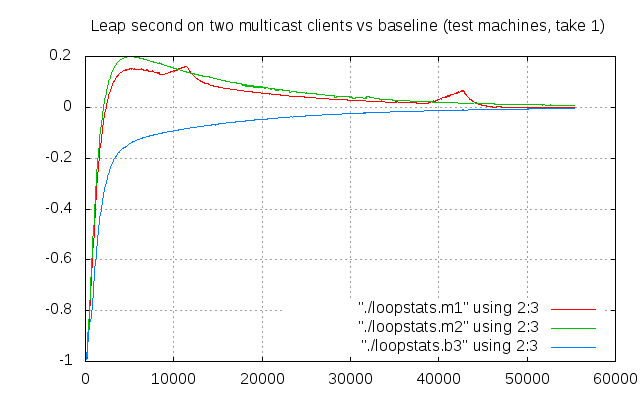
Compared to the “reference curve” (test b3) is not as good, but it’s not terribly bad. The offset from UTC is below 0.2, and we fall below 0.1 seconds offset quite early. But notice those strange spikes of the red line…
Let’s do it once again:
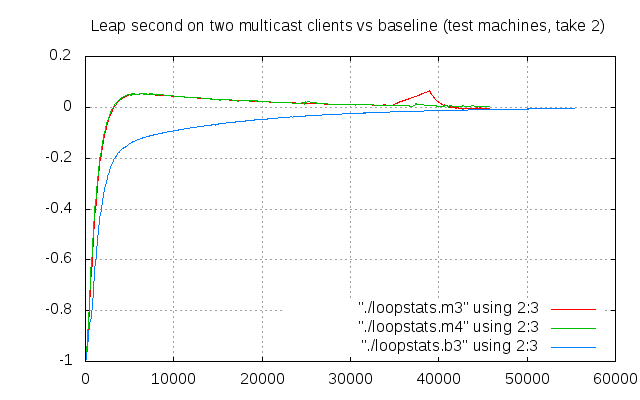
Better 🙂 Oh, and that strange spike in the red line again. I have no explanation for that.
At this point, I think we could say that multicast clients with four servers perform generally well, so let’s go back to the unicast configuration and try to make it work nicely, too. I would like a lot to smoothen those curves spiking up to 0.5-0.6 seconds offset, and make them more similar to the good multicast pattern of my workstation.
What’s the main difference between the multicast tests b1, b2, b3 and these unicast tests u1, u2, u3, u4? Well, they both ran against four servers, but while the “polling” interval is fixed to 64 seconds in multicast (each server spits out a multicast packet every 64 seconds — sort of), unicast client tend to minimize network traffic by spacing out polls when they deem appropriate. Incidentally, the offset takes the bad pattern exactly when they start doing that.
Incidentally?
Let’s see: we force unicast polls to be not less frequent than one every 64 seconds. This makes them more similar to the multicast case, at the expense of more burden placed on the servers and, as a consequence, a slightly worse service for everybody.
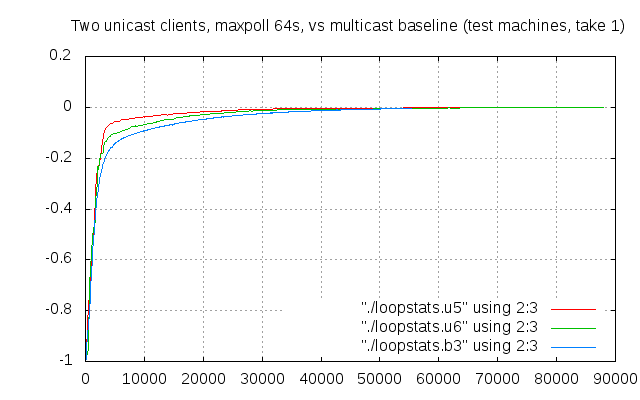
Compared to the baseline test b3, that’s sort of beautiful, right? 🙂 Can we do it again?
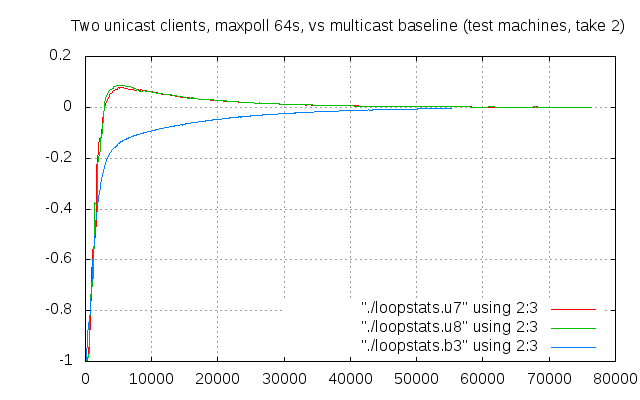
Sort of 🙂 It’s similar to the other multicast tests on the same clients, but without those strange spikes.
One thing which stands out here at this point is that, in almost all cases, when tests are ran simultaneously on two clients, their curves are similar. Uhm… does that hold even if once client is multicast and the other is unicast? New round!

Seems nice 🙂 The curve for unicast is a but more edgy compared to the multicast one, but their pattern is pretty similar. So we may have a chance that the pattern of the curve may depend on when clients are started/restarted, or their past history in general. Maybe, and let me stress “maybe”, two clients started at the same moment have a good chance to converge in a similar way to each other, if they have enough “history” as clients. That would be nice indeed, because it would mean that these clients would never be too much offset from each other.
Conclusion
- this procedure is far from bulletproof, so you’d better test things in your environment; don’t just go for it blindly
- if you use multicast and you have at least four servers, things will probably work quite good
- if you use unicast and you have at least four servers, things will probably work quite good only if you reduce the maximal polling interval to 64 seconds; notice that this has the side effect to increase the load on the server and the network in big environments, thus worsening the quality of the ntp service.
- if you restart all your clients at once (be them unicast or multicast), they will poll the servers together at about the same time. If you have a very large number of clients, that will not only worsen the quality of your NTP service overall, but may also congest the network. If possible, try to group the clients so that, e.g., you restart NTP for one service at a time.
Suggestions for your own tests
Testing these procedures is a matter of doing some things simultaneously on a few machines. I suggest you use cssh (the cluster SSH) or a similar tool, and a Makefile to glue commands together in an intelligent fashion.
Although not perfect, my own makefile can give you some inspiration, so here it goes:
nothing: @echo "Useful targets:" @echo "test: steps to June 30th and performs a test" @echo "reset: resets configuration and the clock, and restarts ntpd" @echo "stopntpd, startntpd, restartntpd: guess what..." @echo "local2client: sets ntp.conf.local for clients" @echo "local2server: sets ntp.conf.local for servers" @echo "install_all: installs software (if needed), and a crontab file" @echo "uninstall_all: removes the crontab file AND NOTHING ELSE!!!" @echo "log: logs TOD around leaptime" reset: stopntpd resetconf resetclock startntpd test: stopntpd june30 localconf startntpd steptest: stopntpd cleanstats plus1 tinkerstart stopntpd: /etc/init.d/ntp stop startntpd: /etc/init.d/ntp start tinkerstart: /usr/sbin/ntpd -p /var/run/ntpd.pid -g -u ntp:ntp -x restartntpd: /etc/init.d/ntp restart resetclock: ntpd -gq # ntpdate 0.debian.pool.ntp.org resetconf: ntp.conf.dist cp ntp.conf.dist /etc/ntp.conf localconf: ntp.conf.local cp ntp.conf.local /etc/ntp.conf local2client: ntp.conf.local.client cp ntp.conf.local.client ntp.conf.local local2server: ntp.conf.local.server cp ntp.conf.local.server ntp.conf.local install_all: install_software install_dirs install_leap_adjust install_crontab install_keys install_software: /usr/sbin/ntpd /usr/sbin/ntpdate /usr/bin/perl /usr/sbin/ntpd: apt-get install -y ntp /usr/sbin/ntpdate: apt-get install -y ntpdate /usr/bin/perl: apt-get install -y perl install_dirs: /var/log/ntpstats /etc/ntp /var/log/ntpstats: -mkdir -m755 /var/log/ntpstats chown ntp:ntp /var/log/ntpstats /etc/ntp: -mkdir -m700 /etc/ntp chown ntp:ntp /etc/ntp install_keys: /etc/ntp ntp.keys cp ntp.keys /etc/ntp chmod 400 /etc/ntp/ntp.keys chown root:root /etc/ntp/ntp.keys install_leap_adjust: /sbin/adjtimex /usr/local/sbin/leap-adjust.pl /usr/local/sbin/leap-adjust.pl: cp leap-adjust.pl /usr/local/sbin /sbin/adjtimex: apt-get install -y adjtimex install_crontab: crontab /etc/cron.d/local-leaptest /etc/cron.d/local-leaptest: cp crontab /etc/cron.d/local-leaptest uninstall_all: uninstall_crontab uninstall_crontab: -rm /etc/cron.d/local-leaptest june30: date --set="2012-06-30 23:45:00" plus1: date --set="+1 second" cleanstats: -rm /var/log/ntpstats/* log: > time.log while true ; do date "+%Y/%m/%d %H:%M:%S.%N" ; done | perl -ne 'print if /23:59:59/ .. /00:00:02/' | tee time.log

James writes:A quick fix for production system facing this problem can be to just change your date as described here: http://www.aviransplace.com/2012/07/01/%E2%80%98leap-second%E2%80%99-bug-wreaks-havoc-across-java-production-systems/
Originally posted by anonymous:
Thanks James. While reading the linked article from Wired, I discovered that it even mentions my posts about NTP. However, there are some inaccuracies that I'd like to point out (very shortly).Saying that the leap second is a step back of the world clocks is to (mis)take the effect with the cause. The leap second is an extra second inserted (or deleted, but that has never happened so far) to re-align UTC to UT1. This means that when a leap second is inserted, we'll have an extra second in that minute: the second number 60. In UTC timestamps:23:59:5823:59:5923:59:6000:00:00The fact that the leap second is implemented in many computer systems by stepping the clock back one second at midnight UTC is kind of a workaround (a bad one, if you ask me), especially when better ways to handle it have been suggested — see my posts for a reference to an article of D.Mills, inventor of NTP.After 40 years from the first leap second, it is still managed by many by a step back of one second; others do it their own way (as Windows, unsurprisingly); others had to invent yet other ways to avoid the traps of bad kernel implementations (ask Google).Yet, I don't think it's likely that Linux kernel developers (or developers of other systems and software, for that matter) will put much effort in handling the next leap second right. Brace yourself, and good luck.
Bob (bobbelderbos.com) writes:Interesting article, thanks for sharing your investigations. I also like your articles on Perl and the recognition story. Aren't you on twitter?
Originally posted by anonymous:
My pleasure ;)Originally posted by anonymous:
Thanks again. What do you mean by "the recognition story", by the way?Originally posted by anonymous:
Not yet, but I'll be as soon as I finish collecting the aftermath of these crazy weekend now known as leapocalipse 🙂
Originally posted by anonymous:
Now yes, it's @brontolinux
Pingback: A small leap for a clock, a giant leap for mankind | A sysadmin's logbook